
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Online Model Houses
- virtual
- 리빌더AI
- scan
- 브린
- ai
- 3Dscan
- Space
- #shoppingmall #fashion #game #mario #mariocart #vr
- VR
- Digital Transformation in Real Estate
- scanning
- nft
- 3D모델링
- AR
- 3D
- modeling
- 리빌더에이아이
- 3Dmodeling
- rebuilderAI
- 3D scanning
- startup
- 3dmodel
- PointCloud
- Sod
- VRIN3D
- Rendering
- VRIN
- #meta #metaverse #spatialcomputing #xr #ar #commerce #3dmodeling #3d #sketchfab #modeling #rendering #ai #reconstruction #3dscan #3dscanning #3dscanner #generativeai #rebuilderai #vrin3d #vrinscan #vrinscanner #vrin3dscanner #vrin
- metaverse
- Today
- Total
RebuilderAI_Blog
[Tech] Neural Radiance Fields 본문
by Geunho Jung (AI researcher / R&D)
Hello. This is RebuilderAI R&D Team.
Today we are sharing about Neural Radiance Fields.
https://rebuilderai.github.io/reconstruction,%20novel%20view%20synthesis/2022/07/12/NeRF.html
Neural Radiance Fields | RebuilderAI
ECCV 2020 NeRF
RebuilderAI.github.io
More available information is here: Home | RebuilderAI
Home | RebuilderAI
리빌더에이아이 테크 블로그
RebuilderAI.github.io
Table of Contents
0. Neural Radiance Fields
1. Differentiable rendering
2. What is Neural Radiance Fields?
3. Limitation of NeRF
0. Neural Radiance Fields
Today, the RebuilderAI R&D team is introducing Neural Radiance Fields (NeRF), which is gaining popularity in the field of Novel view synthetics.
Novel view synthesis means rendering the image that is viewed from a new viewpoint. As interest in VR / AR and metaverse increases, attention and research in view synthesis are also focused. In particular, NeRF has received more attention than others, and various follow-up studies are flooding.
From now on, for those of you who are unfamiliar with or curious about the technology called NeRF, we will introduce What NeRF is and how it works.
1. Differentiable rendering
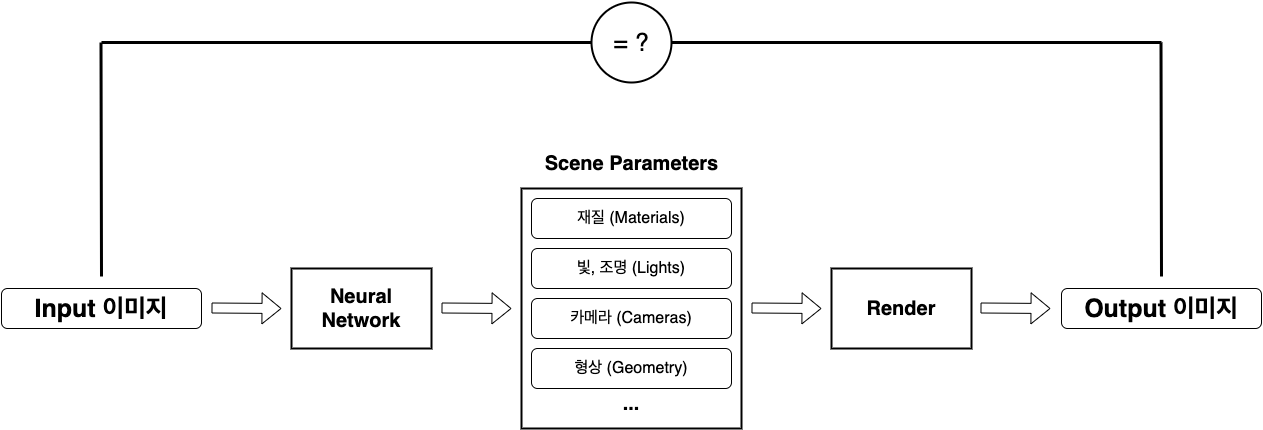
Differentiable rendering is the process of calculating and optimizing gradients from images generated through scene parameters based on the rendering process in computer graphics as shown in [attachment1] below. (Scene parameter; parameter that can explain the scene of geometry, material, light, camera, etc.)

Through this process, we can model the connection between scene parameters and 2D images and solve various problems including inverse rendering in various computers. Especially, the way of utilizing ‘differentiable rendering’ using images as inputs to neural networks, as shown in [attachment2] below, has recently been widely used in tridimensionality-related fields.
2. What is Neural Radiance Fields?
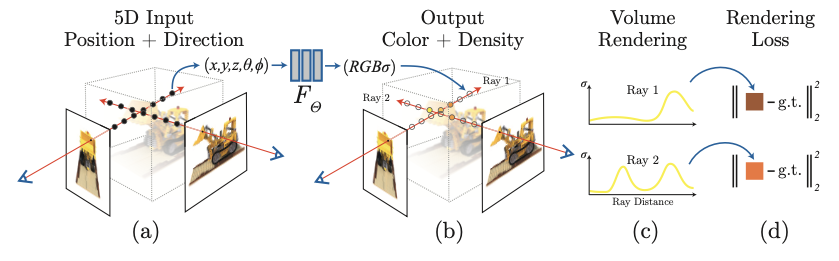
NeRF was first introduced by Mildenhall and others at ECCV in 2020. The full name of the NeRF is NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, and for view synthesis, a method of expressing the scene as a Neural Radiance Field was proposed. Unlike the training method for general deep learning, NeRF does not use a large amount of data sets. But NeRF learns about one scene with various point-in-time image sets and camera parameters and then models for one scene. In addition, an image is used but the image itself does not enter the input of the deep learning network, the ray calculated based on the coordinates is used as the input. Therefore, the learned NeRF network can predict the color and density of the ray and can render the image of a new point in time through volume rendering.
From now on, we will briefly explain how input goes in and how you learn NeRF.
(1) Ray create
As I said before, we create a ray using image coordinates and camera parameters and use it as an input for learning. Ray is a straight line that occurs when a camera flies to a point in a three-dimensional space. Ray can be expressed as follows when the camera's origin and orientation are determined.

(o: camera starting point; d: the direction the camera is looking at; t: the distance from the object to the camera)
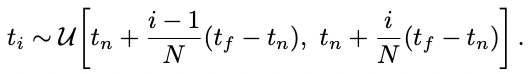
After calculating Ray r, sample the three dimensions point at r moving forward in 3D space. ‘Point sampling’ got Sampling through tlr way, t_n and t_f are variables that represent the closest and longest distance of Voxel. The 3D point (x, y, z) and viewing direction (2D) calculated through Sampling are being input to MLP.
(2) Positional encoding
(3) Optimize MLP

The MLP learned here is simply a function of mapping the 3D point and viewing direction entered as input into color and density. The 3D point first passes through the Fully-connected layer (256 channels + ReLU activation function) on the 8th floor to output the density and 256-dimensional Feature vector. This feature vector, combined with the Viewing direction, predicts the View-dependent Color through one additional Fully-connected layer (128 channels, + ReLU activation function).
(4) Volume rendering
Color and Density predicted by each 3D point are calculated as final Color through Volume rendering. Volume Rendering can express like the below equation. (Reference: Max et al. Optical models for direct volume rendering)

3. Limitation of NeRF
While NeRF has shown high performance and been famous in the View synthesis field, there are a few limitations.
1) Long hours
2) Many images that should be taken from different perspectives
3) Relatively inadequate in 3D reconstruction
Optimizing a scene requires a significant number of images and corresponding camera parameters and a long learning time. Various studies are progressing to solve this problem, and recently, a way to shorten the learning time which takes an hour to minutes, or learn about 100 images with less than 10 images, etc. has been introduced. Instant-GP introduced by NVIDIA reduces the speed of the NeRF to less than 5 minutes. Also, DS-NeRF has suggested a way to utilize Depth information to enable View synthetics with very few images.
As we said before, NeRF is relatively lacking in performance in 3D reconstruction. Compared to ways for 3D reconstruction such as IDR, MVSDF, NeuS, we can see that NeRF 3D reconstruction had poor performance.



