
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 3Dscan
- ai
- metaverse
- 3Dmodeling
- VR
- nft
- startup
- 3D scanning
- scan
- 브린
- AR
- Digital Transformation in Real Estate
- 3dmodel
- Sod
- 리빌더AI
- modeling
- 3D
- VRIN3D
- #meta #metaverse #spatialcomputing #xr #ar #commerce #3dmodeling #3d #sketchfab #modeling #rendering #ai #reconstruction #3dscan #3dscanning #3dscanner #generativeai #rebuilderai #vrin3d #vrinscan #vrinscanner #vrin3dscanner #vrin
- 3D모델링
- Rendering
- Online Model Houses
- scanning
- PointCloud
- virtual
- VRIN
- rebuilderAI
- Space
- 리빌더에이아이
- #shoppingmall #fashion #game #mario #mariocart #vr
- Today
- Total
RebuilderAI_Blog
[Tech] U^2-Net: Going Deeper with Nested U-structure for Salient Object Detection 본문
[Tech] U^2-Net: Going Deeper with Nested U-structure for Salient Object Detection
다육 2022. 8. 11. 16:37by Sanghyeon An (AI research engineer / R&D)
Today we are sharing U^2-Net:Going Deeper with Nested U-Structure for Salient Object Detection | RebuilderAI
U^2-Net:Going Deeper with Nested U-Structure for Salient Object Detection | RebuilderAI
Salient Object Detection model in PR 2020
RebuilderAI.github.io
More available information is here: Home | RebuilderAI
Home | RebuilderAI
리빌더에이아이 테크 블로그
RebuilderAI.github.io
Table of Contents
1. Main Contribution
2. Architecture
3. Experiment results
1. Main Contribution
Network architecture $U^2$-$Net$ was proposed. The network has two levels of nested U structure, designed for Salient object detection, and has three advantages.
1. This structure can capture more contextual information from various scales because it mixes the receptive fields of RSU blocks of different sizes.
2. Pooling operation inside the RSI block allow you to deepen the network while maintaining high resolution without increasing memory and computational costs.
3. It can achieve good performance even if they learn from the beginning since it is not a pre-trained model based on Classification
2. Architecture
- Residual U-block

Local and global contextual information work very importantly in salient object detection. In modern CNN design such as VGG, ResNet, and DenseNet, small convolution filter like 1*1 and 3*3 often appears in feature extraction because they are computationally efficient while taking up less storage space. Figure a~c is an example of using a small filter. These shallow layer features have only local features. This is because the filter is too small to find the global feature. For the shallow layer to obtain global information well in the high-resolution feature map, it has to enlarge the receptive field. The d in the figure is the same block as the inception, but it makes extract both local and global features by enlarging the receptive field using dilated convolution. However, performing these operations on a layer that is not deep (input), requires a lot of memory and computational costs. In this paper, we proposed RSU (ReSidual U-block) inspired by U-Net to solve the above problems and find the intra-stage multi-scale feature. Figure e shows the structure of $RSU-L(C_{in},M,C_{out})$. $C_{in}, C_{out}$ is the number of input, output channels, and M is the number of channels inside the layer. Therefore, RSU consists of three components.
1) Input convolution layer converts the input to an intermediate map $F_1(x)$ with $C_{out}$ channel. This is the plane convolutional layer that extracts the local feature.
2) Secondly, the encoder-decoder structure of L height similar to U-Net. It receives $F_1(x)$ as input and learns to extract and encode multi-scale contextual information $U(F_1(x))$. The larger the size of L, the more pooling operations, the larger range of receptive field and the richer local, global feature. Configuring these parameters allows you to extract multi-scale features better from the input feature map. The multi-scale feature is gradually extracted from the downsampled feature maps and gradually encoded into the high-resolution feature map through upsampling, concatenation, convolution. This process mitigates the loss of details that can be caused by upsampling to large scale.
3. Residual connection combines local feature and multi-scale feature: $F_1(x)+U(F_1(x))$.

Let’s compare it with the original ResNet structure. The original residual block consists of input feature $x$ and convolution layer $F_2, F_1$; for RSU, single-stream convolution was replaced with U-Net like structure, and the original feature was replaced with local feature. The design allows the network to extract features directly from multiple scale in each residual block. In addition, the RSU performs most of the operations on the downsampled feature map, so the computational overhead is small.

Look at the figure above. Blocks such as DSE or INC increase their computation in proportion to the number of channels, while RSU makes little difference.
- $U^2$-$Net$

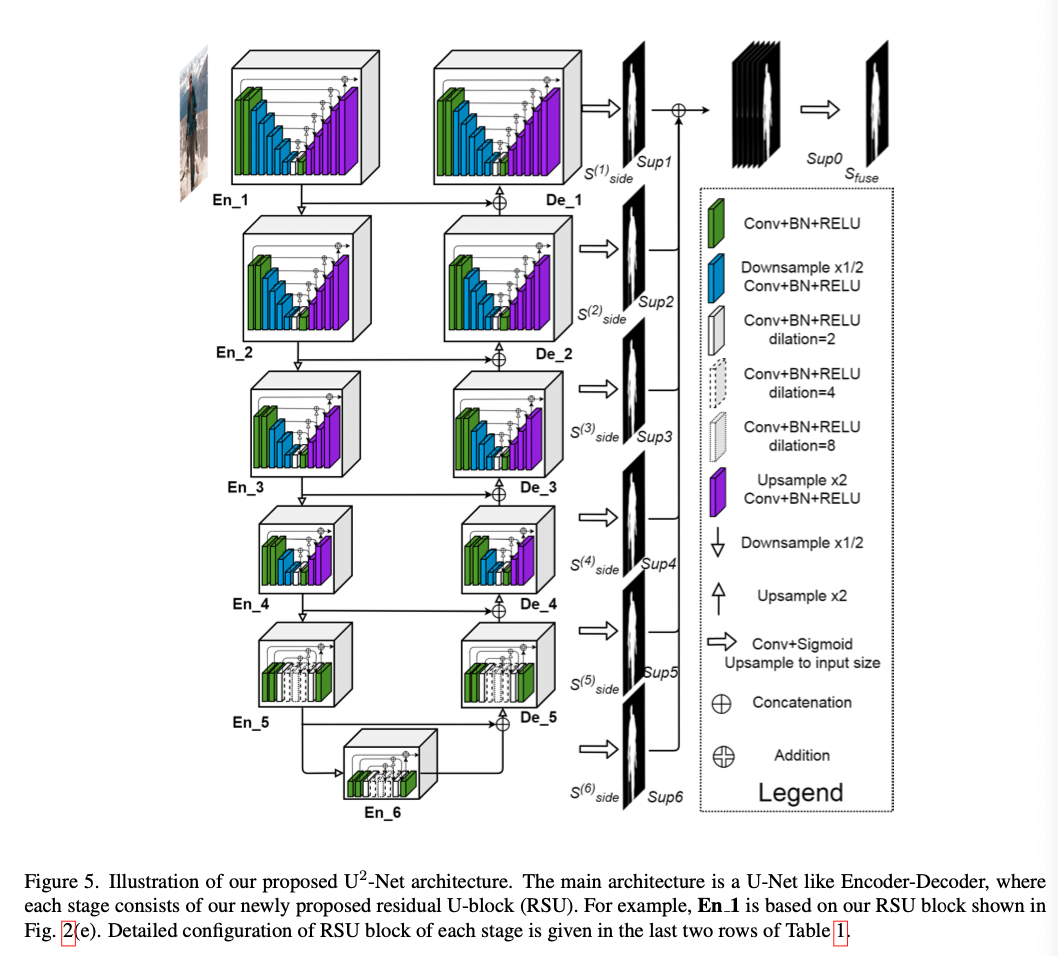
$U^2$-$Net$ is a network created using the RSU block described above, and we can know it has a U structure if we see the figure above. This resulted in an overlaid U structure, which is why it was named $U^2$-$Net$. $U^2$-$Net$ consists of 11 blocks, which can extract intra-stage multi-scale features as much as RSU and aggregates these features more effectively. The encoder and the decoder are symmetrical, and each is made up of the same RSU block in the figure above. It consists of RSU-7, RSU-6, RSU-5, RSU-4 from EN_1 to 4, where each number is L of RSU-L as described above. Also, for EN-5, 6, it consists of RSU-4F, where F means replacing the pooling and upsampling operations of the existing RSU block with the dilated convolution. Therefore, RSU-4F has the same resolution as input feature map and intermediate feature map. Finally, the output of all sides is concatenated to output the final saliency map $S_{fuse}$ via the convolution layer.
- Supervision
During the learning process, deep supervision was used. This effect has been demonstrated in HED and DSS. The loss is as follows. $M$ in $L = \sum_{m=1}^Mw_{side}^{(m)}l_{side}^{(m)} + w_{fuse}l_{fuse}$ is 6 based on the figure above. Because the number of sides is 6. Also, $w$ is the weight of each loss, and $l$ is the standard binary cross entropy.
3. Experiment results

As mentioned above, you can see many datasets are performing well.

Not only quantitative performance but also qualitative performance.
Thank you.
Reference
$U^2$-$Net$ paper
'Technique' 카테고리의 다른 글
| [Tech] AI - CLIP model, flamingo, and GATO (0) | 2022.08.22 |
|---|---|
| [Tech] Structure-from-Motion: COLMAP (0) | 2022.08.18 |
| [Tech] Surface Reconstruction with Implicit Representation (0) | 2022.08.09 |
| [Tech] Neural Radiance Fields (0) | 2022.07.28 |
| [Tech] NeRFactor: Neural Factorization of Shape and Reflectance Under an Unknown Illumination | NeRFactor Review (0) | 2022.07.22 |



