
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 3dmodel
- Rendering
- 3D
- metaverse
- 3Dmodeling
- PointCloud
- VR
- Space
- 3D모델링
- 브린
- Online Model Houses
- 리빌더에이아이
- Digital Transformation in Real Estate
- startup
- 리빌더AI
- VRIN3D
- scanning
- Sod
- #shoppingmall #fashion #game #mario #mariocart #vr
- ai
- 3Dscan
- #meta #metaverse #spatialcomputing #xr #ar #commerce #3dmodeling #3d #sketchfab #modeling #rendering #ai #reconstruction #3dscan #3dscanning #3dscanner #generativeai #rebuilderai #vrin3d #vrinscan #vrinscanner #vrin3dscanner #vrin
- VRIN
- AR
- rebuilderAI
- scan
- virtual
- 3D scanning
- modeling
- nft
- Today
- Total
RebuilderAI_Blog
[Tech] AI - CLIP model, flamingo, and GATO 본문
by Gwan hyeong Koo, Sehyeon Kim (Research Intern)
일반 인공지능을 향하여 | RebuilderAI
Brief introduction to multi-modal learning AI models
RebuilderAI.github.io
More available information is here: Home | RebuilderAI
Home | RebuilderAI
리빌더에이아이 테크 블로그
RebuilderAI.github.io
1. Multimodal learning
2. CLIP, a new model of object recognition
3. Flamingo: Interactive AI technology that maximizes user interaction
4. GATO: General Artificial Intelligence, the last journey
1. Multimodal learning?
People get various forms of data through five sensory organs. The data of various modalities are called "modal". People recognize and understand situations through various forms of data. They receive visual information with their eyes and judge it by sound. Then how is AI currently being studied?
The "vision" field learning visual information through images learns from image or video data. The "natural language" field learning a language through a text-based language can study a language. These two areas are currently leading the flow of AI. But the field of vision and natural language is only advanced in each field, so it's an independent field. In other words, AI models only see with their eyes or use language. So, what can happen when we combine these two areas?
💡 What happens when AI models recognize the fields of "vision" and "natural language" or "voice" together?
The field of learning AI models using various modals like above is called multimodal learning. If we combine traditional "vision" and "natural language" performance can bring us closer to more general artificial intelligence.
2. CLIP, a new model of object recognition
We would like to briefly explain the CLIP model. CLIP is a classification model, but it doesn't simply use image data. The classification model here is a model that classifies a cat if there is a cat in a picture.

In fact, the expression (cat in the above picture) is learned by changing it to a number. For example, if the class of cat is 50, the number 50 instead of the cat is changed to one-hot vector and used by AI to learn. In other words, the meaning of the word "CAT" is not used in the model at all, it just categorizes.
💡 The existing classification model does not learn semantic information that "CAT" has, but simply classifies it stochastically.
But why don't we use the "natural language" here?: giving the answer label to the cat picture as a sentence, not class id.
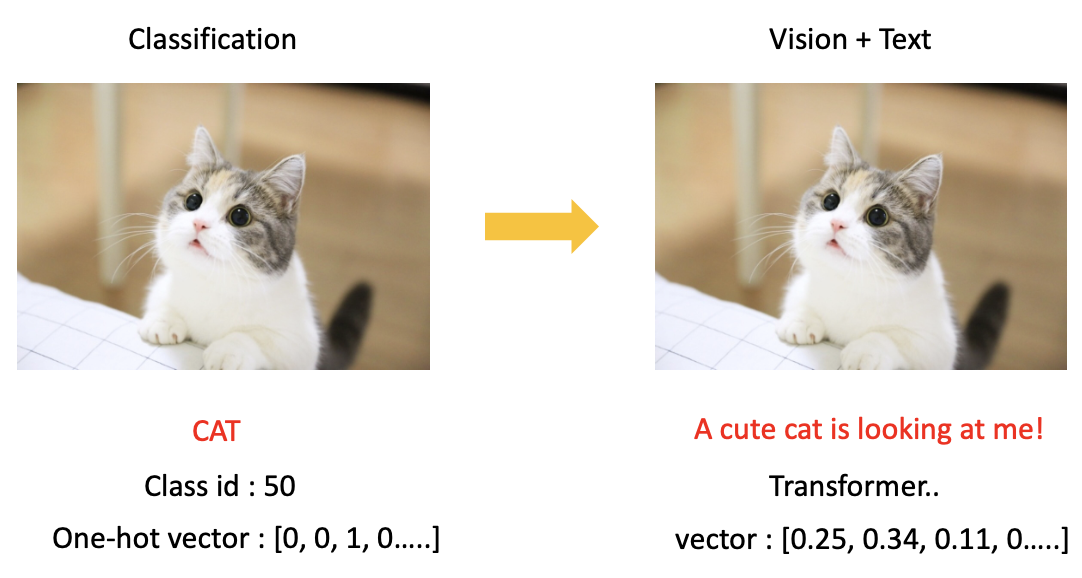
The idea of giving the answer label in semantic sentences and making them learn with images is all about CLIP papers. CLIP has studied a large scale of 400 million images and text (caption) pairs, learned by using the supervision of natural language through text. As a result, they can do a semantic interpretation, not just categorize images.

Therefore, the CLIPmodel can predict things that they haven't learned. This is called zero-shot. Even though we didn't teach the color, mood, and species of this dog. they can infer it well since they learn the correct answer label in natural language.
💡 CLIP builds a powerful zero-shot using two modals: "Vision" and "Text".
3. Flamingo: Interactive AI technology that maximizes user interaction
There is a model that actively utilizes CLIP. Flamingo is a model announced by Google DeepMind in May this year. (Wonder why the title of the thesis is flamingo... haha)
Through CLIP, we now know that semantic interpretations such as text are possible in the "vision" task. Unlike existing classification models, it is now possible to interpret text semantically by looking at an image. Then what about this? Chatting to the user with pictures!
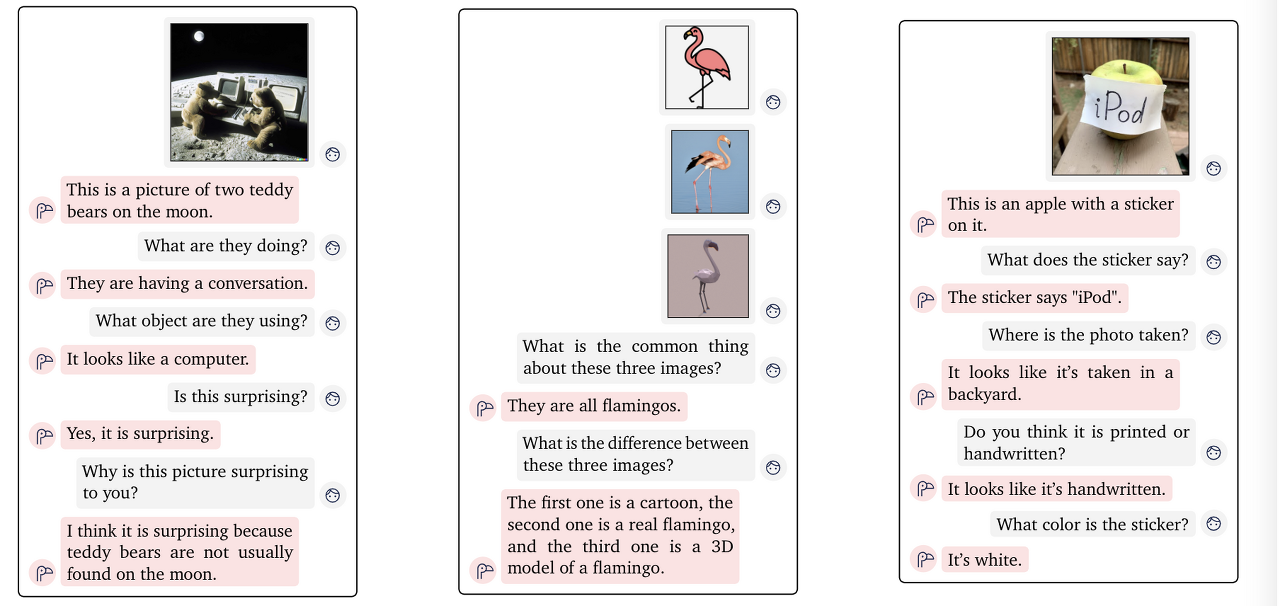
Many chatbots now simply communicate through text. However, we found that using CLIP, AI can interpret visual image data semantically. Flamingo came up with an interactive AI model that transcends images and text. This is possible too.

They infer the context of the next text according to the flow of the text input. For example. when a person inputs the addition of a number, Flamingo knows how the flow of answering the addition next time.
💡 Flamingo is not just an interactive image-text prompt technology, but an example of how AI model can perceive general task.
It is surprising that in the "vision" field, AI models were only possible in one task. However, it can be applied to a more general-purpose task by using two modals: image and task. We think Flamingo can be very useful for search technology, for example, you can order to find a picture of the image you want and to find a similar image if you put a picture of the image you want.

In fact, the Naver Search team has applied the "Omni Search" service to Naver Smart Lens since May this year. It is a search technology that actively utilizes multimodality that combines text and images.
4. GATO: General Artificial Intelligence, the last journey
Google DeepMind released a model called GATO on May 12, following the submission of Flamingo to CVPR on April 29. GATO is a model that is an extension of Flamingo, a universal AI model. They named our Generalist agent "GATO" with over 600 features, including playing Atari, Image captioning, chatting with humans, and building color blocks with robotic arms.

Flamingo was able to do many interactive tasks, but it was not possible to perform tasks in such a different domain like GATO. GATO is a universal artificial intelligence algorithm that can do many tasks.

It's all done by transformers, tokenization, lined up sequentially, and turned the prediction model around. GATO has trained various tasks with 1.2 billion parameters by tokenizing them like this.
- Tokenization method
| continuous | 1024 uniform units |
| discrete | use 0,01204 |
| text | sentence pice [0,320000] |
| image | non-overlapping 18*18 patches -> normalized [-1,1] |
Then is it possible to have a general-purpose artificial intelligence that is really similar to humans if we teach multiple tasks like GATO? Not at all. It's just like hiring agents from different environments at once, putting them in one network. In any case, it can be used for many general-purpose tasks, but it's not the same as humans. It's just a model that is trained with data that is just a probability distribution model so when input comes, output comes.
What's the difference between people and AI? People can think and reason for themselves, but AI is forced to learn, and even that learning is nothing more than learning a lot of data probability statistics.
💡 AI technology is a huge algorithm that can solve many problems that have not been solved. However, it does not work in a similar way to humans. It is simply a product of numerous learning outcomes.
4. Innovative models to make new developments
GPT-3 of Openai was released in early 2020 and has shown tremendous performance. The GPT-3 is currently the largest language model with 150 billion parameters, up to 100 times larger than the previous model, GPT-2. It takes about 300 years to train on a typical cloud platform. The number of words that went into learning is close to 499 billion. CLIP also trained 400 million image-text pairs over 18 days on 592 Tesla V100 GPU. (based on RN50x62 model)
In this way, companies such as Google DeepMind and Open AI continue to create ultra-large AI models based on enormous computing support. However, this learning also uses too much computing power to significantly impact climate change.
What is the future of AI? The AI model gave human convenience, but in reverse, it is a big factor in climate change.
Today, Multimodal learning is nothing more than bringing and using a model that works well in the field of vision and natural language. There was no special algorithm. Big AI models like CLIP are good to be able to use more powerful modalities, but we think it's time for new algorithms to come up.
'Technique' 카테고리의 다른 글
| [Tech] Why do we move from 2D to 3D? (0) | 2022.09.13 |
|---|---|
| [Tech] Semantic Segmentation for Point Clouds (0) | 2022.09.05 |
| [Tech] Structure-from-Motion: COLMAP (0) | 2022.08.18 |
| [Tech] U^2-Net: Going Deeper with Nested U-structure for Salient Object Detection (0) | 2022.08.11 |
| [Tech] Surface Reconstruction with Implicit Representation (0) | 2022.08.09 |



