
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- metaverse
- scan
- Space
- 3D
- Online Model Houses
- 리빌더AI
- 3dmodel
- 3D scanning
- ai
- 3Dscan
- VRIN
- rebuilderAI
- startup
- 3D모델링
- AR
- modeling
- VR
- Rendering
- PointCloud
- Digital Transformation in Real Estate
- 3Dmodeling
- 리빌더에이아이
- virtual
- 브린
- scanning
- #meta #metaverse #spatialcomputing #xr #ar #commerce #3dmodeling #3d #sketchfab #modeling #rendering #ai #reconstruction #3dscan #3dscanning #3dscanner #generativeai #rebuilderai #vrin3d #vrinscan #vrinscanner #vrin3dscanner #vrin
- VRIN3D
- nft
- #shoppingmall #fashion #game #mario #mariocart #vr
- Sod
- Today
- Total
RebuilderAI_Blog
[Tech] Semantic Segmentation for Point Clouds 본문
by Sanghyeon AN (AI research engineer / R&D)
Today we are sharing Semantic Segmentation for Point Clouds | RebuilderAI
Semantic Segmentation for Point Clouds | RebuilderAI
Semantic segmentation survey
RebuilderAI.github.io
More available information is here: Home | RebuilderAI
Home | RebuilderAI
리빌더에이아이 테크 블로그
RebuilderAI.github.io
Table of Contents
1. Datasets
2. Evaluation Metrics
3. Methods
Semantic Segmentation for 3D Point clouds
Recently, we are working on a salient object detection project in 2D space based on image/video. However, simply detecting using 2D images is limited in reaching our goal of uniformly segmenting as few images as possible. Therefore, we would like to introduce 3D knowledge to the existing model or proceed with segmentation in 3D. In the process, we conducted research to consider Segmentation in the 3D point cloud, and we would like to share the overall aspects of the field.

According to Deep Learning for 3D Point Clouds: A Survey [1], deep learning techniques for 3D point clouds are classified as follows: It is largely divided into Classification, Object detection and tracking, and Segmentation, and we will only cover Segmentation this time.
3D point cloud Segmentation
1. Datasets
Datasets for 3D point cloud segmentation are obtained by different types of sensors. These datasets are used to develop algorithms of various challenges. The Dataset list is as follows.

2. Evaluation Metrics
Case of 3D point cloud segmentation, the two most frequently used metrics are OA(Overall Accuracy), and mloU(mean Intersection over Union).
Each formula is below.
$OA = {\sum_{i=1}^N c_{ii} \over \sum_{j=1}^N\sum_{k=1}^N c_{jk}}$,
*N: the number of classes / $c_{ii}, c_{jk}$: the value in the $N \times N$ confusion matrix [2].
$mIoU = {1 \over C}\sum_{c=1}^C {TP_c \over TP_c + FP_c + FN_c}$
*$C$: the number of classes / $TP_c,\FP_c,\FN_c$: the True Positive, False Positive, False Negative of each class $c$ in the Confusion matrix [3].
3. Methods
3D point cloud segmentation requires an understanding of the global geometric structure and fine-grained details of each point. Depending on the Segmentation unit, 3D point cloud segmentation is divided into three categories.
1. Semantic Segmentation (Scene level)
2. Instance Segmentation (Object level)
3. Part Segmentation (Part level)
This time, we deal with only Semantic Segmentation.
3.1 3D Semantic segmentation
Given a point cloud, the goal of semantic segmentation is to divide each point into semantic subsets. It can also be categorized into four categories according to the paradigm.
1. Projection-based
2. Discretization-based
3. Point-based
4. Hybrid-based
The first step in techniques-based projection and discretization is to turn point cloud into intermediate regular representation. Then reflect the intermediate segmentation result into the raw point cloud. But point-based techniques go straight from an irregular point cloud.
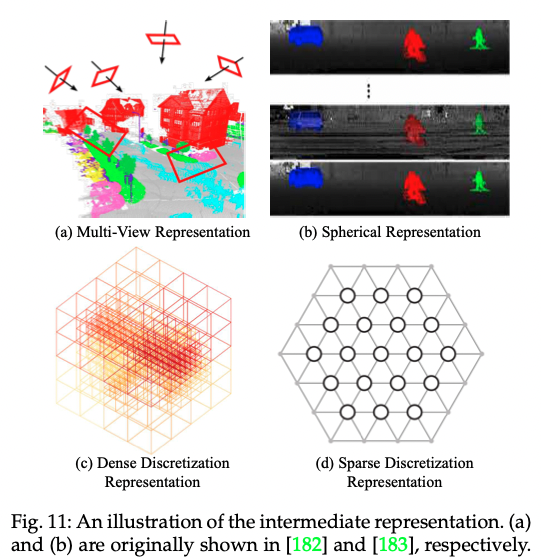
3.1.1 Projection-based Methods
These skills generally project 3D point clouds into 2D images, including multi-view/spherical images.
Multi-view Representation
Most of these techniques use a 3D segmentation model by selecting a virtual multi-view point and projecting a 3D point cloud to that view point. (a) above shows multi-view representation briefly.
First, there is a way to (1) project a 3D point cloud into 2D and (2) put the image into a segmentation model to obtain pixel scores, and (3) fuse the reprojection scores for different views [4]. Similarly, there is a way to create RGB and depth snapshots of the point cloud using multiple camera positions and to perform pixel-wise labeling using a 2D segmentation network [5]. In this method, the predicted score using RGB and depth images are fused by residual correction.
Another method is to use tangent convolution based on the assumption that the point cloud is sampled in the locally euclidean surface [6]. This technique projects the local surface geometry into a virtual tangent plane, after which the tangent convolution is computed directly from the surface geometry. This technique is highly scalable and shows that it can also handle large-scale point clouds.
Overall, multi-view segmentation techniques are sensitive to viewpoint selection and occlusion. In addition, these methods did not widely use geometric and structural information because they inevitably caused a loss of information in the projection process.
Spherical Representation
These techniques project 3D point cloud as 2D grid representation in a spherical projection to put 3D point cloud into a 2D CNN [7,8]. If they use a sparse and irregular point cloud as it is, it is inefficient and wasteful. So, to prevent these problems and to obtain more compressed representation, they project with sphere coordinate system. Spherical projection maintains more information than single view projection and is suitable for labeling of irregular lidar point clouds. However, this intermediate representation cannot avoid discretization errors and occlusion problems.
Figure (b) above shows the spherical presentation simply.
3.1.2 Discretization-based Methods
These techniques typically convert point clouds to dense/sparse discrete representation such as volumetric and sparse permutohedral lattices and proceed with segmentation based on 3D CNN.
Dense Discretization Representation
Early methods voxelated point clouds to dense-grid and utilized 3D convolution.
By dividing the point cloud into voxel units and putting the intermediate product into a 3D CNN to perform voxel-wise segmentation, all points in the voxel are allocated with the same label [9]. These techniques are severely limited in performance depending on the size of the voxel and the artifact. To solve this problem and achieve global consistent semantic segmentation, model SEGCloud that mapped prediction of coarse voxel to point cloud generated from 3D-FCNN through deterministic trilinear interpolation and used FC-CRF is proposed [10].
Kernel-based interpolated VAE architecture is proposed to encode the local geometrical structure from each voxel [11]. Instead of using binary occupancy representation, we use RBF to obtain continual representation for each voxel and capture the points distribution in each voxel. The VAE is used to map the point distribution of each voxel to a compact latent space. In addition, sturdy feature learning is achieved using Group-CNN. The regular data format helped improve performance by making 3D convolution available immediately. However, the voxelization process has no choice but to appear discretization artifact and information loss. Generally, high resolution of voxel causes high memory and computation cost, while low resolution causes loss of detail. Therefore, it is important to choose an appropriate grid resolution.
Sparse Discretization Representation
Volumetric representation are naturally sparse because they have a small proportion of the number of non-zero values. Therefore, it is not efficient to apply a dense CNN. Thus, a submanifold sparse convolutional network based on indexing structure was proposed [12]. This technique showed an excellent effect in reducing memory and computational cost. This sparse convolution can control the density of the extracted features. Submanifold sparse convolution can effectively process high-dimensional and spatially sparse data.
A network for similar 3D video perception has been proposed [13]. It excels at processing high-dimensional data using a generalized sparse convolution. Also, it strengthens the consistency using a trilateral-stationary conditional random field.
On the other hand, a network using the BCL (Bilateral Convolution Layer) has been proposed [14]. This technique interpolates the raw point cloud into a permutohedral sparse lattice and then applies BCL to convolve the in-use part of the sparsely filled lattice. This output interpolates back to the raw point cloud. Additionally, this technique makes the joint processing of multi-view images and point clouds flexible.
After that, a network that can effectively handle large point clouds has been proposed [15].
3.1.3 Hybrid Methods
To utilize all available information more effectively, several methods to learn multi-modal in 3D scan have been proposed. A joint 3D-multi-view network using a differentiable back-projection layer was proposed [16], and unified point-based framework for learning 2D texture was proposed [17]. [17] applied a point-based network to extract local geometric features and global context from a sparsely sampled set of points without voxelization. Multi-view PointNet has also been proposed to aggregate features obtained from 2D multi-view images and spatial geometric features in classical point cloud space [18].
3.1.4 Point-based Methods
A point-based network is a straightforward use of an irregular point cloud. However, the point cloud is unordered and unstructured, so it is not good to apply it directly to a general CNN. However, PointNet has been proposed to learn point-specific features and global features through shared MLP. Point-based network based on PointNet has been proposed a lot until recently. These techniques are roughly divided into pointwiseMLP, point convolution, RNN-based, and graph-based.
The rest of the point-based method will continue in the next posting.
Reference
[1] Guo, Y., Wang, H., Hu, Q., Liu, H., Liu, L., & Bennamoun, M. (2020). Deep learning for 3d point clouds: A survey. IEEE transactions on pattern analysis and machine intelligence, 43(12), 4338-4364.
[2] T. Hackel, N. Savinov, L. Ladicky, J. Wegner, K. Schindler, and M. Pollefeys, “Semantic3D.net: A new large-scale point cloud classification benchmark,” ISPRS, 2017.
[3] J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “SemanticKITTI: A dataset for semantic scene understanding of lidar sequences,” in ICCV, 2019.
[4] F. J. Lawin, M. Danelljan, P. Tosteberg, G. Bhat, F. S. Khan, and M. Felsberg, “Deep projective 3D semantic segmentation,” in CAIP, 2017.
[5] A. Boulch, B. Le Saux, and N. Audebert, “Unstructured point cloud semantic labeling using deep segmentation networks.” in 3DOR, 2017.
[6] M. Tatarchenko, J. Park, V. Koltun, and Q.-Y. Zhou, “Tangent convolutions for dense prediction in 3D,” in CVPR, 2018.
[7] B. Wu, A. Wan, X. Yue, and K. Keutzer, “SqueezeSeg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3D lidar point cloud,” in ICRA, 2018.
[8] B. Wu, X. Zhou, S. Zhao, X. Yue, and K. Keutzer, “SqueezeSegV2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud,” in ICRA, 2019.
[9] J. Huang and S. You, “Point cloud labeling using 3D convolutional neural network,” in ICPR, 2016.
[10] L. Tchapmi, C. Choy, I. Armeni, J. Gwak, and S. Savarese, “SEGCloud: Semantic segmentation of 3D point clouds,” in 3DV, 2017.
[11] H.-Y. Meng, L. Gao, Y.-K. Lai, and D. Manocha, “VV-Net: Voxel vae net with group convolutions for point cloud segmentation,” in ICCV, 2019.
[12] B. Graham, M. Engelcke, and L. van der Maaten, “3D semantic segmentation with submanifold sparse convolutional networks,” in CVPR, 2018.
[13] C. Choy, J. Gwak, and S. Savarese, “4D spatio-temporal convnets: Minkowski convolutional neural networks,” in CVPR, 2019.
[14] H. Su, V. Jampani, D. Sun, S. Maji, E. Kalogerakis, M.-H. Yang, and J. Kautz, “SplatNet: Sparse lattice networks for point cloud processing,” in CVPR, 2018.
[15] R.A.Rosu,P.Schu ̈tt,J.Quenzel,andS.Behnke,“LatticeNet:Fast point cloud segmentation using permutohedral lattices,” arXiv preprint arXiv:1912.05905, 2019.
[16] A. Dai and M. Nießner, “3DMV: Joint 3D-multi-view prediction for 3D semantic scene segmentation,” in ECCV, 2018.
[17] H.-Y. Chiang, Y.-L. Lin, Y.-C. Liu, and W. H. Hsu, “A unified point-based framework for 3D segmentation,” in 3DV, 2019.
[18] M. Jaritz, J. Gu, and H. Su, “Multi-view pointNet for 3D scene understanding,” in ICCVW, 2019.
'Technique' 카테고리의 다른 글
| [Tech] Why do we move from 2D to 3D? (0) | 2022.09.13 |
|---|---|
| [Tech] AI - CLIP model, flamingo, and GATO (0) | 2022.08.22 |
| [Tech] Structure-from-Motion: COLMAP (0) | 2022.08.18 |
| [Tech] U^2-Net: Going Deeper with Nested U-structure for Salient Object Detection (0) | 2022.08.11 |
| [Tech] Surface Reconstruction with Implicit Representation (0) | 2022.08.09 |



